
Samenvatting
Doel
De invloed van casemixverschillen binnen diagnosegroepen op het gestandaardiseerde ziekenhuissterftecijfers (HSMR) onderzoeken en het huidige HSMR-model verbeteren.
Opzet
Beschrijvend, analyse van modellen.
Methode
Wij berekenden de HSMR’s en de gestandaardiseerde sterftecijfers op diagnosegroepniveau (SMR’s) van 84 Nederlandse ziekenhuizen over een periode van 5 jaren met behulp van 2 HSMR-modellen. Beide modellen corrigeerden we voor de ernst van de diagnose bij opname (hoofddiagnose volgens de ‘International classification of diseases’(ICD)-9) aan de hand van zwaarteklassen. De indeling in zwaarteklassen was in het gebruikelijke model (model 1) gebaseerd op mortaliteitcijfers volgens de WHO, terwijl ons aangepaste ‘Nederlandse’ model (model 2) was gebaseerd op de Nederlandse ziekenhuismortaliteit. De HSMR- en SMR-uitkomsten en bijbehorende c-statistics van beide modellen werden vergeleken om te toetsen in hoeverre de modellen adequaat corrigeerden voor ICD-9-codes met hoog of laag sterfterisico.
Resultaten
Model 1 corrigeerde bij 40 van de 48 geanalyseerde diagnosegroepen niet adequaat voor casemixverschillen op ICD-9-hoofddiagnoseniveau; model 2 corrigeerde niet adequaat voor 25 diagnosegroepen. De c-statistics voor model 2 waren beter dan voor model 1. De verschillen in SMR-uitkomsten tussen model 2 en model 1 varieerden van -63% tot 202%, afgemeten aan de uitkomst berekend met model 1. Bij de HSMR varieerden deze verschillen van -6,7% tot 4,3%.
Conclusies
Het huidige HSMR-model voor Nederland corrigeert onvoldoende voor casemixverschillen op het niveau van de ICD-9-hoofddiagnose. Een model met zwaarteklassenindeling van ICD-9-codes op basis van de geobserveerde ziekenhuismortaliteit in Nederland maakt een betere, zij het niet perfecte, correctie mogelijk. Ter verbetering van het HSMR-model wordt aanbevolen deze ‘Nederlandse’ zwaarteklassenindeling toe te passen.
artikel
Inleiding
De belangstelling in Nederland voor het gebruik van het gestandaardiseerde ziekenhuissterftecijfer, de ‘hospital standardised mortality ratio’ (HSMR), neemt de laatste jaren sterk toe. Dit hangt samen met de toenemende focus op het meten, verbeteren en transparant maken van de kwaliteit van zorg in ziekenhuizen.
Het HSMR-model (zie uitlegkader) is voor Nederland ontwikkeld door Kiwa Prismant in samenwerking met Dr Foster Intelligence, het Engelse HSMR-kenniscentrum. Het model corrigeert voor patiëntkenmerken (‘casemix’) zoals leeftijd, geslacht en aandoening, ontleend aan de Landelijke Medische Registratie (LMR). In oktober 2010 verspreidde de stichting ‘Dutch Hospital Data’ (DHD) de (H)SMR-rapportage 2007-2009 met verdieping naar diagnosegroepen en patiëntencategorieën onder Nederlandse ziekenhuizen, met voor ieder ziekenhuis specifieke informatie. Ieder ziekenhuis kreeg zodoende inzicht in de eigen gestandaardiseerde sterfte (‘standardised mortality ratios’; SMR’s) behorende bij 50 diagnosegroepen (zie uitlegkader). Dit biedt de mogelijkheid gericht te werken aan kwaliteitsverbeteringen.
De Inspectie voor de Gezondheidszorg stimuleert dit HSMR-gebruik zoals beschreven in de basisset prestatie-indicatoren.1 Verder is er een publieke behoefte aan het vergelijken van ziekenhuizen middels openbaar gemaakte ziekenhuissterftecijfers (www.nfu.nl/index.php?id=166).2-4 Er zijn echter ook twijfels over de betrouwbaarheid,5,6 validiteit,7,8 en bruikbaarheid van het model.9,10 In hoeverre zijn de huidige HSMR- en SMR-uitkomsten nog vertekend door meetfouten?
In deze publicatie beschrijven wij voor Nederland het effect van meetfouten die kunnen optreden als niet adequaat wordt gecorrigeerd voor casemixverschillen binnen diagnosegroepen. In Medisch Contact is een voorbeeld van de invloed van casemixverschillen op de SMR beschreven voor de diagnosegroep ‘cerebrovasculaire aandoening’ (CVA).11 Hierbij werd onvoldoende gecorrigeerd voor casemixverschil tussen bloedige CVA (hersenbloeding of subarachnoïdale bloeding; mortaliteit circa 35%) en niet-bloedige CVA (herseninfarct; mortaliteit circa 10%). Bij inadequate correctie hiervoor bleken ziekenhuizen met verhoudingsgewijs veel patiënten met een hersenbloeding of subarachnoïdale bloeding in het nadeel ten opzichte van ziekenhuizen die veel patiënten met een herseninfarct opnamen.
De oorzaak van dit verschijnsel hangt samen met de huidige correctiemethode, die is gebaseerd op een zwaarteclassificatie van de WHO. Deze vormt vermoedelijk geen adequate weergave van de feitelijke casemix in Nederland. In ons onderzoek vergeleken wij daarom de uitkomsten van het traditionele model met die van een model waarin de correctie was gebaseerd op de Nederlandse casemix. De centrale vraag was in hoeverre het aangepaste, Nederlandse model een verbetering zou inhouden. Dat onderzochten wij niet alleen voor de CVA-diagnosegroep, maar ook voor de overige diagnosegroepen.
Methode en data
Voor de modelanalyse werd, met toestemming van DHD, gebruik gemaakt van een geanonimiseerde LMR-dataset over de jaren 2005-2009 van 84 Nederlandse ziekenhuizen; ziekenhuizen werden geïncludeerd als de gegevens voldoende volledig in de LMR waren ingevoerd. Voor de HSMR-berekeningen gebruikten wij het ‘Dr Foster Intelligence’-model zoals Kiwa Prismant dat vanaf 2009 heeft toegepast.12 Vanaf 2010 tellen hierbij alleen nog maar klinische opnamen en dagopnamen met sterfte mee.
Casemixcorrectie binnen diagnosegroepen
Een goed standaardisatiemodel corrigeert onder andere voor de verschillen in ernst van aandoening die tot uiting komen in verschillen in de hoofddiagnosen volgens de ‘International classification of diseases’(ICD)-9. Er kunnen meer dan 1000 verschillende ICD-9-diagnosecodes voorkomen bij een HSMR-berekening. Deze worden geclusterd in 50 diagnosegroepen volgens de ‘Clinical classification software’ (CCS; www.hcup-us.ahrq.gov/toolssoftware/ccs/ccsfactsheet.jsp#what). De casemixcorrectie vond plaats op het niveau van deze diagnosegroepen, waardoor binnen een CCS-diagnosegroep geen onderscheid gemaakt werd tussen ernstige en minder ernstige aandoeningen op ICD-9-niveau.
Om vertekening door de clustering tegen te gaan, heeft Dr Foster Intelligence een extra correctievariabele ingevoerd die aan iedere diagnose bij opname een zwaarteklasse toekent, afhankelijk van de ICD-9-hoofddiagnose. De zwaarte varieert van 1 (licht) tot 7 (zwaar) en is gebaseerd op een indeling naar sterfterisico van de WHO. Voor een aantal ICD-9-codes heeft Dr Foster Intelligence om onbekende redenen geen extra correctie ingevoerd; opnamen met deze ICD-9-codes krijgen in de classificatie een waarde 0. Bij deze waarde vindt geen extra correctie plaats.
De modellen vergeleken
In ons onderzoek draaide het om de indeling van ICD-9-codes in zwaarteklassen. Wij onderzochten in hoeverre de zwaarteclassificatie in het ‘Dr Foster Intelligence’-model spoort met de geobserveerde ziekenhuismortaliteit van ICD-9-codes in Nederland en in hoeverre dit invloed heeft op de HSMR en SMR. Daartoe berekenden wij met 2 modellen de HSMR- en SMR-waarden van de 84 ziekenhuizen over 2005-2009. De modellen waren identiek op het volgende verschil na:
(a) model 1 maakt gebruik van de zwaarteclassificatie volgens Dr Foster Intelligence;
(b) model 2 maakt gebruik van een zwaarteclassificatie die gebaseerd was op de ziekenhuismortaliteit in Nederland in de jaren 2005-2009 per voorkomende ICD-9-code.
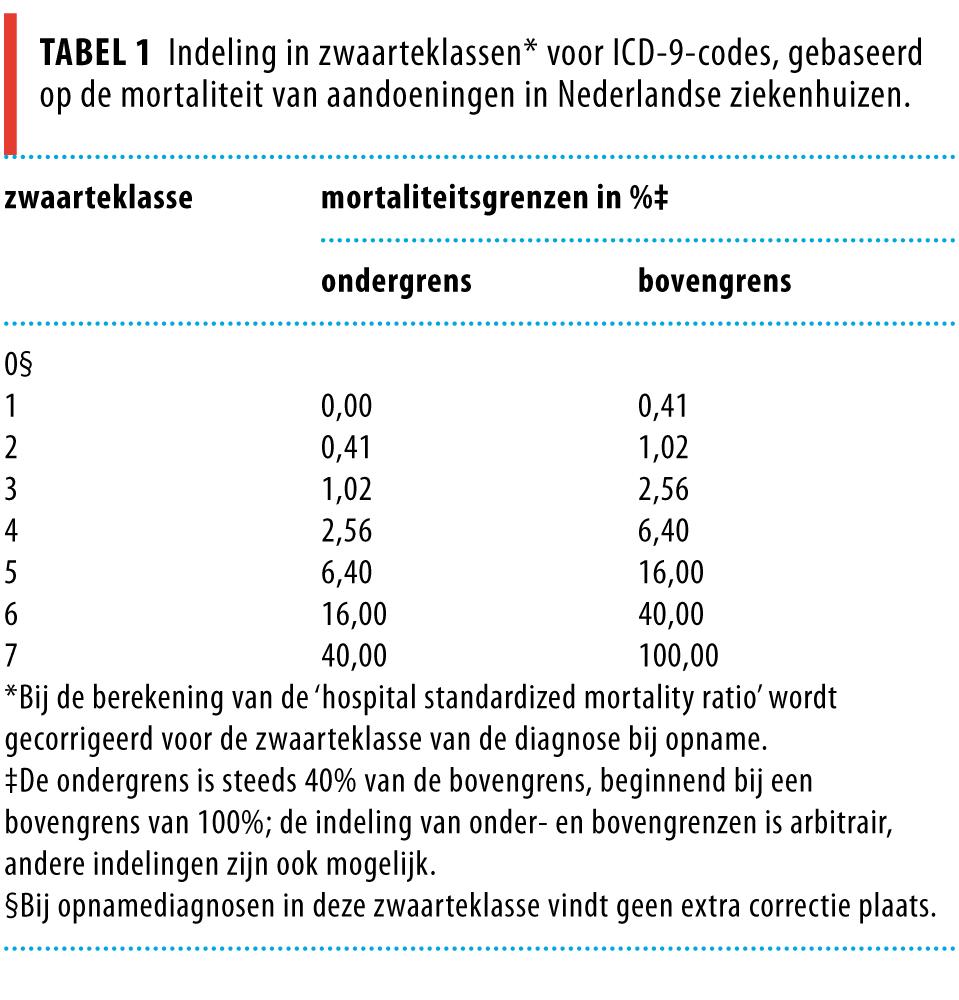
Tabel 1 toont de mortaliteitsgrenzen die wij kozen voor de indeling in 7 zwaarteklassen. Voor een beperkt aantal ICD-9-codes stelden wij de zwaarteklasse in verband met representativiteit op 0, omdat die codes door te weinig ziekenhuizen (minder dan 5) waren gebruikt.
Beoordeling casemixverschillen
Om de invloed van casemixverschillen binnen een CCS-diagnosegroep aan te kunnen tonen, verdeelden wij per CCS-diagnosegroep alle in die groep meetellende opnamediagnosen over:
(a) een ‘hoogrisico’-subgroep van ICD-9-hoofddiagnosen met hogere ruwe ziekenhuismortaliteit;
(b) een ‘laagrisico’-subgroep van ICD-9-hoofddiagnosen met lagere ruwe ziekenhuismortaliteit.
De ICD-9-codes werden zodanig ingedeeld in ‘hoog risico’ of ‘laag risico’ dat het aantal sterfgevallen binnen een diagnosegroep bij benadering evenredig verdeeld was over deze 2 subgroepen. De vraag was in hoeverre een onevenredig groot aantal patiënten in een van de 2 subgroepen invloed had op de SMR van een individueel ziekenhuis.
Bij de analyse keken we naar de verhouding (ratio) van de mortaliteit van de hoogrisico-subgroep en de laagrisico-subgroep per CCS-diagnosegroep voor alle ziekenhuizen tezamen. Zonder standaardisatie is deze ratio groter dan 1, maar na perfecte standaardisatie zou de ratio 1 moeten bedragen. Een ziekenhuis ondervindt dan geen voor- of nadeel bij relatief veel of weinig opnamen in een van de 2 subgroepen.
Wij bepaalden voor beide modellen per CCS-diagnosegroep in hoeverre deze ratio van 1 afweek. Als een model statistisch significant afweek van 1 (dat wil zeggen: 1 lag buiten het 95%-BI van de ratio), dan concludeerden wij dat dat model niet adequaat corrigeerde voor het casemixverschil binnen die CCS-diagnosegroep.
Vergelijking HSMR’s en SMR’s
Wij vergeleken de HSMR- en SMR-uitkomsten van beide modellen op 3 punten:
(a) procentueel: in hoeverre verschillen de SMR’s berekend volgens model 1 en model 2 per CCS-diagnosegroep, per ziekenhuis?
(b) significantiescore, dat wil zeggen: wijst de SMR op een sterfte die statistisch significant hoger, lager of niet afwijkend van het gemiddelde is?
(c) voorspellende waarde, uitgedrukt in ‘c-statistic’ per CCS-diagnosegroep (zie uitlegkader).
De procentuele verschillen in uitkomst tussen de modellen 1 en 2 werden berekend met de formule SMRdelta = (SMRmodel 2/SMRmodel 1 - 1) × 100%. Deze verschillen werden weergegeven in een frequentieverdeling. Hetzelfde gebeurde voor de HSMR’s.
Resultaten
Wij analyseerden 48 CCS-diagnosegroepen die een zinvolle splitsing in hoogrisico- en laagrisico-ICD-9-codes toelieten. Het ging hierbij om 2.851.973 opnamen met 149.279 sterfgevallen. Van 2 CCS-diagnosegroepen, ‘prostaatkanker’ en ‘aspiratiepneumonie door voedsel of braken’, was splitsing niet zinvol en deze vielen dus af.
Ratios van gestandaardiseerde sterftecijfers
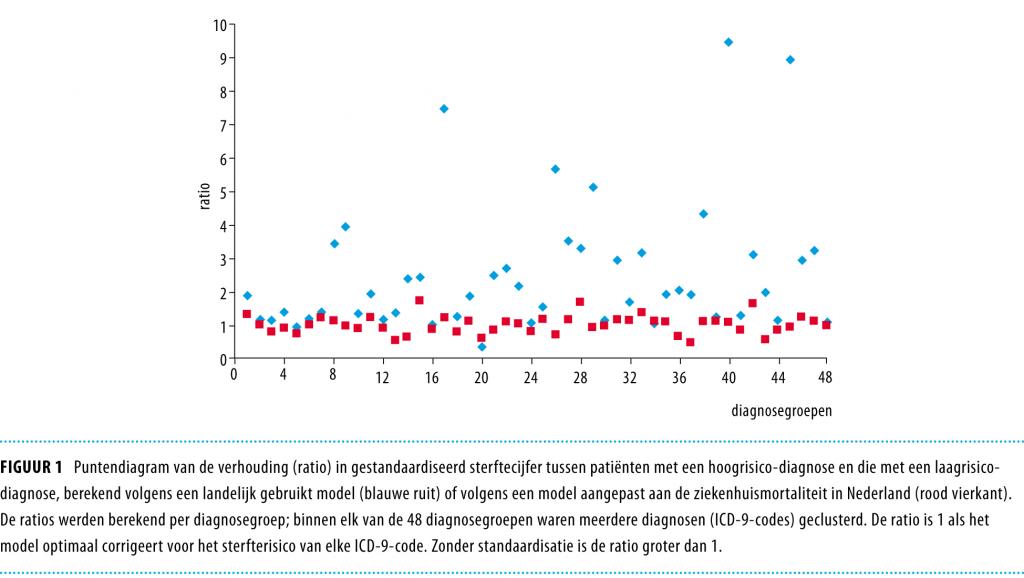
Figuur 1 toont een puntendiagram met de ratios van hoogrisico- en laagrisico-gestandaardiseerde sterftecijfers voor 48 CCS-groepen voor beide modellen. Bij model 1 weken 40 van de 48 ratios statistisch significant af van de waarde 1 en bij model 2 weken 25 ratios af. De afwijkingen van model 1 waren zichtbaar groter dan die van model 2.
Verschillen in HSMR en SMR
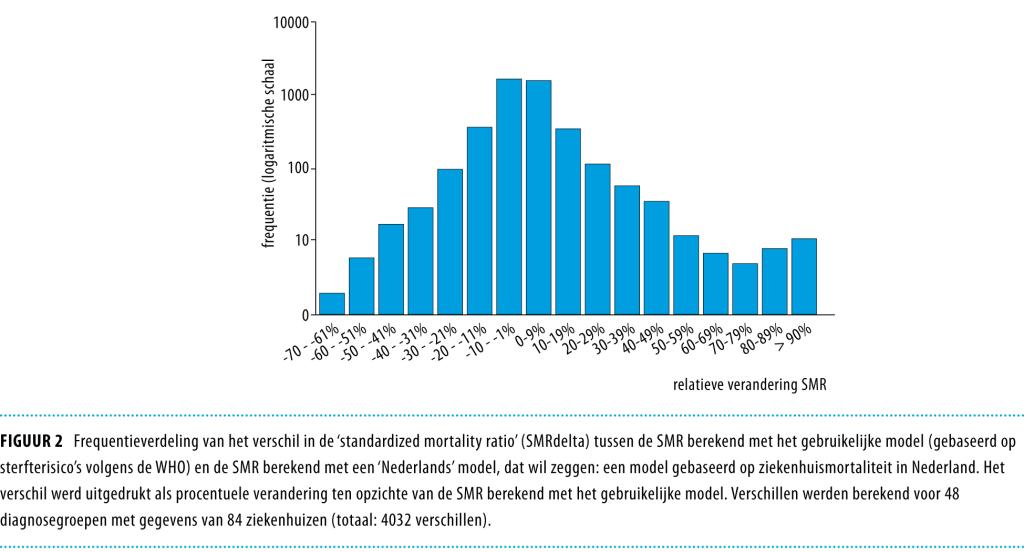
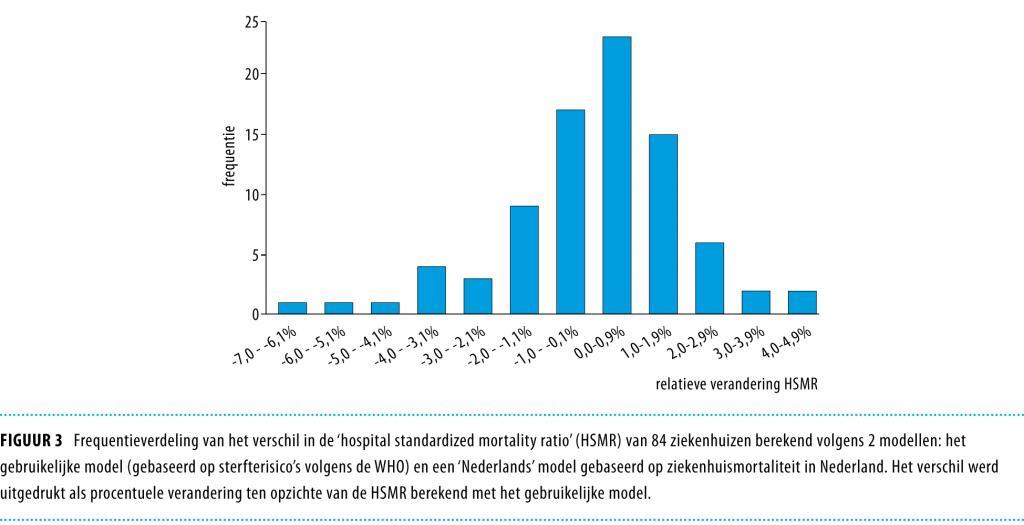
Wij berekenden de procentuele verschillen tussen SMR’s (SMRdelta) voor 48 diagnosegroepen en 84 ziekenhuizen; dit leverde 4032 uitkomsten op. Figuur 2 geeft de frequentieverdeling van de verschillen. Op dezelfde wijze maakten wij een frequentieverdeling van de verschillen tussen de HSMR’s van de 84 ziekenhuizen, berekend met model 1 en model 2 (figuur 3). De uiterste waarden van de SMRdelta waren -63% en 202% (SD: 14,6). De uiterste waarden van de HSMR’s waren -6,7% en 4,3% (SD: 2,0).
Voor beide modellen werd de ‘c-statistic’ per CCS-diagnosegroep bepaald (tabel 2). Bij 38 diagnosegroepen vertoonde model 2 een hogere c-statistic dan model 1; de verschillen varieerden van 0,1% tot 17,5%. Bij 8 diagnosegroepen was de c-statistic van model 2 wat lager.
Tot slot stelden wij per diagnosegroep vast bij hoeveel ziekenhuizen de SMR volgens het ene model wees op een statistisch significant hogere of lagere sterfte en volgens het andere model niet (zie tabel 2).Model 1 gaf bij 391 van de 4032 SMR’s aan dat de sterfte statistisch significant verhoogd was ten opzichte van het gemiddelde. Bij 87 hiervan (22%) was de sterfte volgens model 2 niet hoger dan gemiddeld. Model 2 gaf bij 352 SMR’s significant hogere sterfte aan; bij 48 hiervan (14%) was de sterfte volgens model 1 niet verhoogd.
Beschouwing
In dit onderzoek werden de SMR- en HSMR-uitkomsten van 2 modellen onderling vergeleken. Deze uitkomsten bleken substantieel te verschillen op het niveau van CCS-diagnosegroepen, zoals te zien aan de volgende waarnemingen:
(a) De relatieve verschillen tussen de SMR’s van model 1 en die van model 2 varieerden aanzienlijk, van -63% tot 202%. Dit betekent dat het modeltype dat werd toegepast grote invloed had op de waarde van de SMR’s van ziekenhuizen, onafhankelijk van de kwaliteit van zorg. Het volgende rekenvoorbeeld laat zien wat de grootte van de relatieve verschillen betekent: stel SMRmodel 1 op100 SMR-punt; als SMRmodel 2 = 50 SMR-punt, dan bedraagt het verschil -50%, en als SMRmodel 2 = 200 SMR-punt, dan is het verschil +100%. De standaarddeviatie van de verdeling van relatieve verschillen bedroeg 14,6%; ter vergelijking: de standaarddeviatie van de verdeling van de 4032 SMR’s bedroeg 45 SMR-punt.
(b) De modellen verschilden bij het aanwijzen van significant hoge sterfte. 22% van de SMR’s die volgens model 1 op significant verhoogde sterfte wezen, deden dat niet volgens model 2. Omgekeerd was 14% van de SMR’s die volgens model 2 op verhoogde sterfte wezen, volgens model 1 juist niet verhoogd. Dit betekent dat ‘best practices’ – net als rangordes van ziekenhuizen – die gebaseerd zijn op SMR-berekeningen, kunnen verschillen afhankelijk van de modelkeuze.
Op HSMR-niveau waren de verschillen minder sterk dan op SMR-niveau.
Welk model is nu ‘beter’ en waarom? Wij menen dat model 2 een betere, zij het niet perfecte correctie bewerkstelligt in de Nederlandse situatie, op grond van de volgende overwegingen:
(a) De verdeling van de ratios van hoogrisico- en laagrisico gestandaardiseerde sterfte had bij model 2 een geringere spreiding (0,47-1,7) dan bij model 1 (0,35-9,5) en bevatte minder vaak significante afwijkingen van 1 (25 bij model 2 versus 40 bij model 1).
(b) De c-statistics van model 2 zijn aanzienlijk beter dan die van model 1.
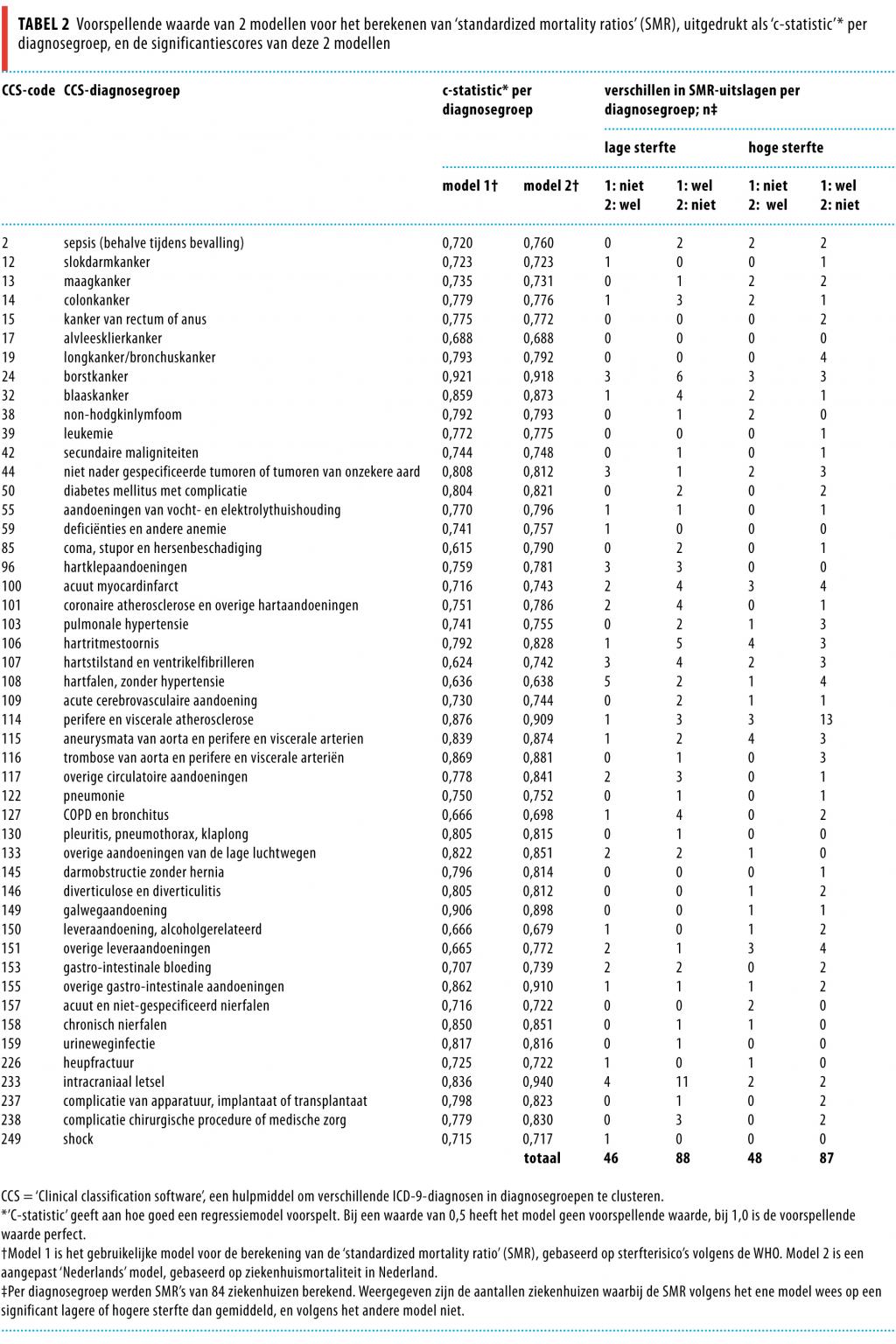
(c) De indruksvaliditeit (‘face validity’) van model 1 is beperkt. Zo is in figuur 4 op het eerste gezicht al duidelijk dat de zwaarteklassen volgens model 1 niet correleren met de mortaliteit in Nederlandse ziekenhuizen voor de afzonderlijke diagnosen binnen de CCS-diagnosegroepen ‘Overige circulatoire aandoeningen’ en ‘Overige leveraandoeningen’; model 2 vertoont wel een goede correlatie. Andere CCS-diagnosegroepen vertonen soortgelijke patronen. Mogelijk verschillen Nederlandse mortaliteitspatronen van die waarop de WHO-zwaarteklassen zijn gebaseerd.
HSMR’s en SMR’s worden steeds vaker gebruikt bij het verbeteren van kwaliteit van zorg in ziekenhuizen. Vooral diagnosegroepen met significant hoge sterfte worden kritisch doorgelicht door zorgprofessionals. Hierbij is van belang dat de juiste diagnosegroepen worden aangepakt. Uit ons onderzoek blijkt echter dat het huidige model voor Nederland niet adequaat corrigeert voor casemixverschillen binnen CCS-diagnosegroepen. Daardoor kan een substantieel aantal SMR’s ten onrechte aangemerkt worden als statistisch significant hoger dan het gemiddelde. Omgekeerd wordt ook een substantieel aantal SMR’s aangemerkt als niet-significant verhoogd, terwijl de verhoging vermoedelijk wél statistisch significant is. Ziekenhuizen hebben derhalve nog onvoldoende zicht op sterke en zwakke punten van de verleende zorg. Bij de analyse van gestandaardiseerde ziekenhuissterftecijfers in de rapportages over 2007-2009, dient men hierop bedacht te zijn; tabel 2 kan hierbij helpen.
In dit onderzoek bleek één bron van ongecorrigeerde variatie de uitkomsten van SMR- en HSMR-berekeningen al te kunnen vertekenen. Eerder onderzoek heeft laten zien dat variaties in codering,5 het effect van bijzondere medische verrichtingen,7 de onvergelijkbaarheid van context,8 variaties in ziekenhuissterfte van terminaal geïndiceerde patiënten en het effect van heropnamen eveneens van invloed kunnen zijn op de HSMR van een ziekenhuis.13,14 Daarom is er behoefte aan een beter inzicht in de aard en impact van ongecorrigeerde variatiebronnen voordat men de HSMR-methodiek betekenisvol kan inzetten, zoals bij het werken aan verbetering van kwaliteit en patiëntveiligheid in ziekenhuizen. Deze behoefte wordt steeds groter naarmate het HSMR-model verder wordt ontwikkeld en de besluitvorming rond openbaarmaking van het gestandaardiseerde ziekenhuissterftecijfer voortschrijdt.
Conclusies
Het huidige HSMR-model voor Nederland corrigeert onvoldoende voor casemixverschillen op het niveau van ICD-9-hoofddiagnosen. De oorzaak hangt samen met een inadequate indeling van ICD-9-codes in zwaarteklassen. Een betere correctie wordt mogelijk na aanpassing van deze indeling op geleide van de ziekenhuismortaliteit in Nederland. Bij vergelijking van SMR-waarden volgens het oorspronkelijke model en volgens een nieuwe berekening springen substantiële verschillen op CCS-diagnosegroepsniveau in het oog. Op ziekenhuisniveau (HSMR-waarden) zijn de verschillen beperkt. Ter verbetering van het HSMR-model bevelen wij aan de zwaarteklassenindeling te baseren op de Nederlandse ziekenhuismortaliteit.
Leerpunten
Voor de berekening van gestandaardiseerde ziekenhuissterftecijfers (HSMR en SMR) wordt een model gebruikt dat corrigeert voor vertekenende factoren.
Een van de vertekenende factoren is de ernst van de diagnose bij opname; correctie vindt plaats door diagnoses in te delen in zwaarteklassen.
De indeling van diagnoses in zwaarteklassen is in het huidige HSMR-model gebaseerd op sterfterisico’s volgens de WHO.
Een betere correctie is mogelijk met een HSRM-model met zwaarteklassen die zijn gebaseerd op de Nederlandse ziekenhuismortaliteit.
Bij gebruik van de gestandaardiseerde sterftecijfers die in 2010 in Nederland zijn verspreid, dient men er rekening mee te houden dat mogelijk niet goed gecorrigeerd is voor casemixverschillen binnen diagnosegroepen.
Uitleg
De HSMR in het kort De ‘hospital standardised mortality ratio’ (HSMR) is de verhouding tussen de in een ziekenhuis waargenomen sterfte en de verwachte sterfte, die bepaald is door een vergelijking van patiëntkenmerken met het landelijke gemiddelde. De uitkomst wordt genormeerd op 100. Een HSMR boven de 100 duidt op een hogere sterfte dan gemiddeld, onder de 100 op een lagere sterfte. Als de berekening wordt toegepast op één van de 50 diagnosegroepen dan spreken we van de ‘standardised mortality ratio’ (SMR).
Het HSMR-model dat in 2010 in Nederland gebruikt werd, corrigeert voor de volgende patiëntkenmerken: jaartal van ontslag, leeftijd bij opname, geslacht, opname-urgentie, comorbiditeit (charlsonindex), sociaaleconomische status, maand van opname, verblijfplaats patiënt voorafgaand aan de opname, diagnosegroep bij opname en gedeeltelijk voor zwaarte van de aandoening binnen de diagnosegroep.
Iedere diagnosegroep is samengesteld uit een aantal onderliggende aandoeningen, aangeduid met ‘International classification of diseases’(ICD)-9-codes zoals vastgelegd door de ‘Clinical classification software’ (CCS). Dit hulpmiddel clustert verschillende ICD-9-diagnosen in een hanteerbaar aantal betekenisvolle categorieën, aangeduid als ‘CCS-diagnosegroepen’. Deze hebben een relatief hoge mortaliteit en omvatten tezamen meer dan 80% van de totale ziekenhuissterfte.
C-statistic Deze statistische maat geeft aan hoe goed een regressiemodel voorspelt. Daarbij wordt de sterftevoorspelling van iedere opname vergeleken met de uitkomst: wel of niet overleden. Bij een waarde van 0,5 is er geen voorspellende waarde: bij 50% van de opnamen was de voorspelling goed, bij 50% niet goed. Bij 1 is de voorspellende waarde perfect. De c-statistic van het HSMR-model dat in Nederland wordt toegepast ligt boven de 0,85.
Literatuur
Inspectie voor de Gezondheidszorg. Veiligheidsindicatoren ziekenhuizen 2010 t/m 2012. Utrecht: IGZ; 2010.link
Tweede Kamer der Staten-Generaal. Antwoorden op kamervragen van Koser Kaya over het bericht dat ziekenhuizen zwijgen over hun sterftecijfers. Aanhangsel der Handelingen. 2008-2009, 1422. Den Haag: SDU, 2009.link
Sterftecijfer nog niet publiek in 2010. Med Contact. 2009;64:1320.link
Van den Bosch WF, Roozendaal KJ, Silberbusch J, Wagner J. Variatie in codering patiëntgegevens beïnvloedt gestandaardiseerd ziekenhuissterftecijfer (HSMR). Ned Tijdschr Geneeskd. 2010;154:A1189 Medline.NTvG
Pieter D, Kool RB, Westert GP. Beperkte invloed gegevensregistratie op gestandaardiseerd ziekenhuissterftecijfer (HSMR). Ned Tijdschr Geneeskd. 2010;154:A2186 Medline.NTvG
Van den Bosch WF, Graafmans WC, Pieter D, Westert GP. Hartcentra en het effect van bijzondere medische verrichtingen op de gestandaardiseerde ziekenhuissterfte. Ned Tijdschr Geneeskd. 2008;152:1221-7 Medline.NTvG
Mohammed MA, Deeks JJ, Girling A, et al. Evidence of methodological bias in hospital standardised mortality ratios: retrospective database study of English hospitals. BMJ. 2009;338:b780 Medline. doi:10.1136/bmj.b780
Lilford R, Mohammed MA, Spiegelhalter D, Thomson R. Use and misuse of process and outcome data in managing performance of acute medical care: avoiding institutional stigma. Lancet. 2004;363:1147-54 Medline. doi:10.1016/S0140-6736(04)15901-1
Penfold RB, Dean S, Flemons W, Moffatt M. Do hospital standardized mortality ratios measure patient safety? HSMRs in the Winnipeg Regional Health Authority. Healthc Pap. 2008;8:8-24 Medline.
Pleizier CM, Geerlings W, Pieter D, Boiten J. Patiëntenmix beïnvloedt HSMR. Medisch Contact. 2010;65:1777-9.
Jarman B, Pieter D, van der Veen AA, et al. The Hospital Standardised Mortality Ratio: a powerful tool for Dutch hospitals to assess their quality of care? (2009). Qual Saf Health Care. 2010;19:9-13 Medline. doi:10.1136/qshc.2009.032953
Black N. Assessing the quality of hospitals. BMJ. 2010;340:c2066 Medline. doi:10.1136/bmj.c2066
Van den Bosch WF, Kelder HC, Wagner C. Predicting hospital mortality among frequently readmitted patients: HSMR biased by readmission. BMC Health Serv Res. 2011;11:57 Medline. doi:10.1186/1472-6963-11-57
Artikelinformatie
Citeer dit artikel als



HSMR verbeterd model
De conclusie, dat het huidige HSMR-model voor Nederland onvoldoende corrigeert voor casemix verschillen op het niveau van de ICD-9-hoofddiagnose is heel belangrijk.[1] Casemix correctie is essentieel als men ziekenhuissterftecijfers gaat vergelijken. Als het huidig HSMR model geen goede vergelijking toelaat, is het dan wel verantwoord is om deze cijfers openbaar te maken ? Zeker omdat deze ‘transparantie’ gevoed is op behoefte om ziekenhuissterftecijfers te vergelijken. Recent is aangetoond hoe moeilijk, voor de meeste mensen, het interpreteren van ziekenhuissterftecijfers is. [2] Maar er is een veel fundamenteler probleem. De HSMR steunt op administratieve data.. Verschillende studies,[3,4] hebben aangetoond dat specifieke klinische databases, een grotere betrouwbaarheid hebben, zeker als het gaat om het verrichten van risicostratificatie, basis voor de case-mix correctie. Ook P.Aylin geeft aan in zijn publicatie dat goede klinische databases superior zijn wat betreft casemix analyse. [5] Natuurlijk is het zo dat de administratieve databases, landelijk beschikbaar zijn, goedkoop en dankzij de ICD-codes gemakkelijk vergelijkbaar zijn. Toch lijkt essentieel dat de evaluatie en de transparantie van de kwaliteit van zorg start op basis van de meest correcte data. Is de HSMR dan waardeloos? Neen, zolang er geen betere informatie is, kan de HSMR gebruikt worden. Maar met de wetenschap dat op basis van deze administratieve gegevens een alarm gegeven wordt, dat er eventueel iets mis is. Een alarm dat eerst moet geverifieerd worden op basis van correcte , gevalideerde data, met een optimale casemix correctie en dit met optimale methodieken. Als men zich dit realiseert is de vraag of de HSMR gegevens openbaar gemaakt moeten worden feitelijk een gewetensvraag.
Luc Noyez, cardio-thoracaal chirurg, Radboud Universiteit Nijmegen Medisch Centrum
Literatuur.
1. Bosch van den WF, Spreeuwenberg P, Wagner C. Gestandaardiseerd ziekenhuissterftecijfer (HSMR): correctie voor ernst hoofddiagnose kan beter. Ned Tijdschr Geneeskd 2011;155:A 3299
2. Donelan K, Rogers RS, Eisenhauer A, Mort E, Agnihotri AK. Consumer comprehension of surgeon performance data for coronary bypass procedures. Ann Thorac Surg 2011;91:1400-1406.
3. Mack MJ, Herbert M, Prince S, Dewey TM, Magee MJ, Edgerton JR. Does reporting of coronary artery bypass grafting from administrative databases accurately reflect actual clinical outcomes? J Thorac Cardiovasc Surg 2005;129-1309-1317.
4. Shahian DM, Silverstein T, Lovett AF, Wolf RE, Normand SLT. Comparison of clinical and administrative data sources for hospital coronary artery bypass graft surgery reports cards. Circulation 2007;115:1518-1527.
5. Aylin P; Bottle A; Majeed A. Use of administrative data or clinical databases as predictors of risk of death in hospital: comparison of models. BMJ 2007; 334: 1044-1052